Security

Protect what is yours
Source code, design documents, specifications, customer data — none of it touches an external AI service.
From AI infrastructure to team-wide adoption.
Bring AI to your embedded teams — without sending a line of code outside the company.
Cloud AI is tempting. But your source code, designs, and customer specs can't leave the building.
You need an AI environment built around three pillars — security, model quality, and team adoption.
Source code, design documents, specifications, customer data — none of it touches an external AI service.
Hundreds of models exist. Few survive production. We evaluate them so you can pick the right one for each task.
Not just power users. Policies, training, and operations make AI part of how the team works.
Infrastructure, coding tools, knowledge integration, training — we design, build, and run the whole stack so your team can focus on shipping.
On-prem, closed network, or cloud — designed and built to your security requirements.
AI chat, coding agents, and IDE integrations developers use every day.
Choose and evaluate models against your use case, performance, cost, and security constraints.
AI that reads your specs, design documents, internal rules, and past materials.
Developer workshops, usage policies, practical guides, and visibility into how AI is used.

We'll design a configuration
that fits your environment and security requirements.
Combine AI chat, coding agents, and internal knowledge — and AI shows up across investigation, implementation, review, testing, and maintenance.
Map control logic, drivers, and middleware structures fast.
Surface related specs and past design decisions from your internal documents.
Write and revise C/C++, Python, test code, and build scripts.
Reviews shaped by your coding conventions, design rules, and past bug patterns.
Unit tests, edge cases, log analysis, root-cause investigation.
Bottleneck analysis and improvement proposals for models and code.
We combine open-model execution environments with closed-model access — sized to your data sensitivity and internal policies.

We build dedicated hardware inside your facility. Code never leaves the premises.

We build and operate dedicated hardware in a partner data center. Less ops on your side.

We build a dedicated VPC environment on a cloud vendor's infrastructure. Lower upfront investment. Start in weeks, not months.

Run the latest closed models — Claude Opus, Claude Sonnet, and others — in your own virtual private cloud. Your data is never used to train someone else's model.
Tell us your environment and operational policy,
and we'll propose the right configuration.
We raise AI development quality across three dimensions — model selection, output code performance, and organizational knowledge. Starting with model selection: the right model depends on the task, security envelope, and quality bar. We continuously evaluate models and deliver a catalog matched to your work.
Pick the right model from your security-cleared catalog based on task characteristics.

Open models have advanced enough to be a practical choice — even on-prem or in closed networks. For work where code can't leave the company, they often perform well enough.
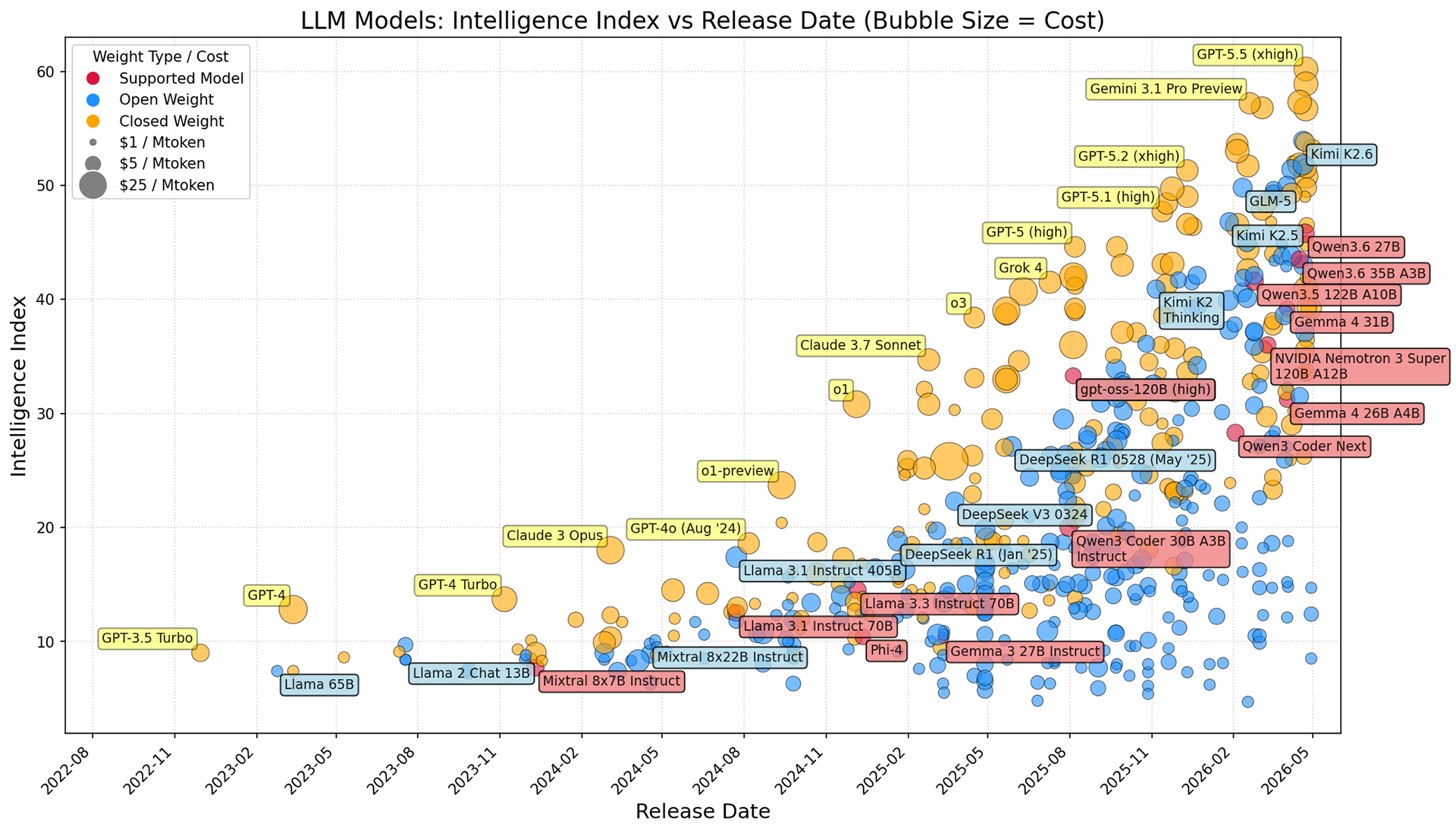
Skip the evaluation grind. We verify each model and document use cases, speed, and licensing for you.
Verified open models
* As of April 2026. New models are added regularly.

APEX (Agentic Performance Engineering eXperience) is Fixstars' proprietary framework that packages 20 years of accumulated performance-engineering expertise into a form AI agents can apply. The code it produces matches—and in some projects exceeds—the optimization work of veteran engineers.
General performance optimization — automatic rewriting for CPU-GPU sync reduction, memory layout, torch.compile, and more.
TensorRT acceleration for PyTorch inference — automatic, functionally-equivalent rewrites that avoid graph breaks.
Discover new optimization patterns — the LLM autonomously finds and accumulates novel optimizations not in the existing playbook.
* More capabilities are added on an ongoing basis.
Large-batch processing, prompt pre-caching, TensorRT conversion, etc.
TensorRT conversion, PTQ, custom CUDA kernels as plugins, etc.
bf16 mixed precision, NHWC memory-format fix, torch.compile, etc.
Enable OpenCL UMat, persistent UMat retention, etc.
* Measured on Fixstars internal benchmarks. For reference only.
See the full methods and results
behind each speedup in our service brief.
We apply our knowledge-loop methodology to your organization, raising development quality across the team. Throughout the engagement, we cultivate the mechanisms for AI to reference your veterans' know-how and internal standards.
Naming rules, design judgments, quality criteria — the team-wide ground rules.
How routine work — reviews, code analysis, documentation — gets done.
Role assignments, decision criteria, the reasoning behind past decisions.
* At launch, we support the setup. Through the project, your knowledge base grows.
Organize internal know-how and rules into reusable knowledge
Set AI roles and rules to match the project
AI references knowledge to make decisions and suggestions
Code or suggestions in a form ready for real work
Update results and grow the knowledge base
An AI environment isn't done at launch. Hands-on developer workshops, regular model updates, and visibility into usage and cost — we keep AI part of how your team works, day in and day out.
Practical training that turns AI-driven development into a team habit.
Sample workshop topics

Run the latest models flexibly and continuously, even in local environments.
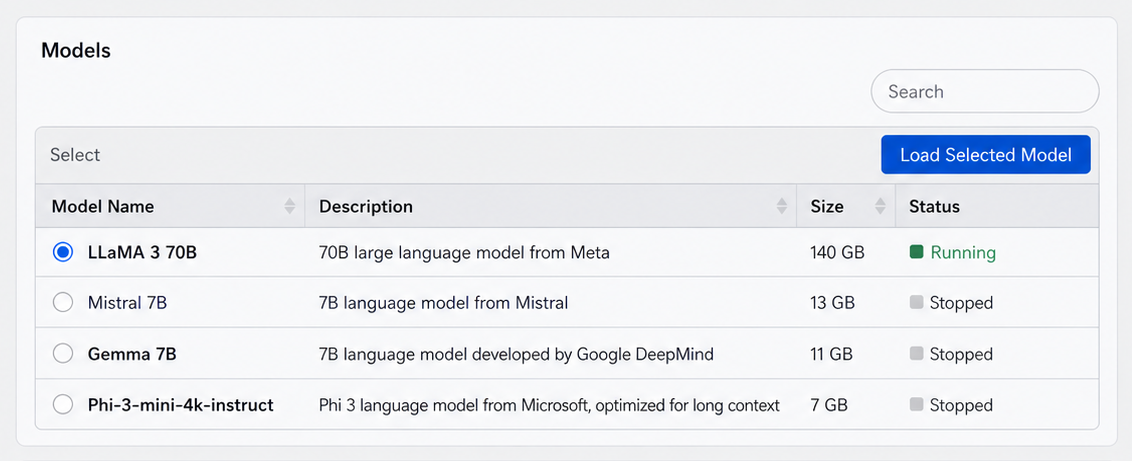
Visualize per-model usage, cost, latency, and throughput — and tune the environment as it runs.
From build-out to adoption — tailored to your situation.
* Timelines vary by project scale and requirements
We map your security requirements, development phase, and existing environment.
Design the infrastructure, models, tooling, and knowledge structure.
Stand up infrastructure, models, tools, and management features.
Run with a small team. Surface issues. Refine operations.
Roll out org-wide. Workshops instill use patterns. Operations get optimized.
Tell us your current setup and goals.
We'll propose how to get there.
From secure infrastructure to team adoption of AI-driven development.
One-stop support for embedded AI.
One PDF: what we deliver, sample configurations, the model list, and operational rules.
Get the briefFor configurations, quotes, and technical questions.
Get in touch