

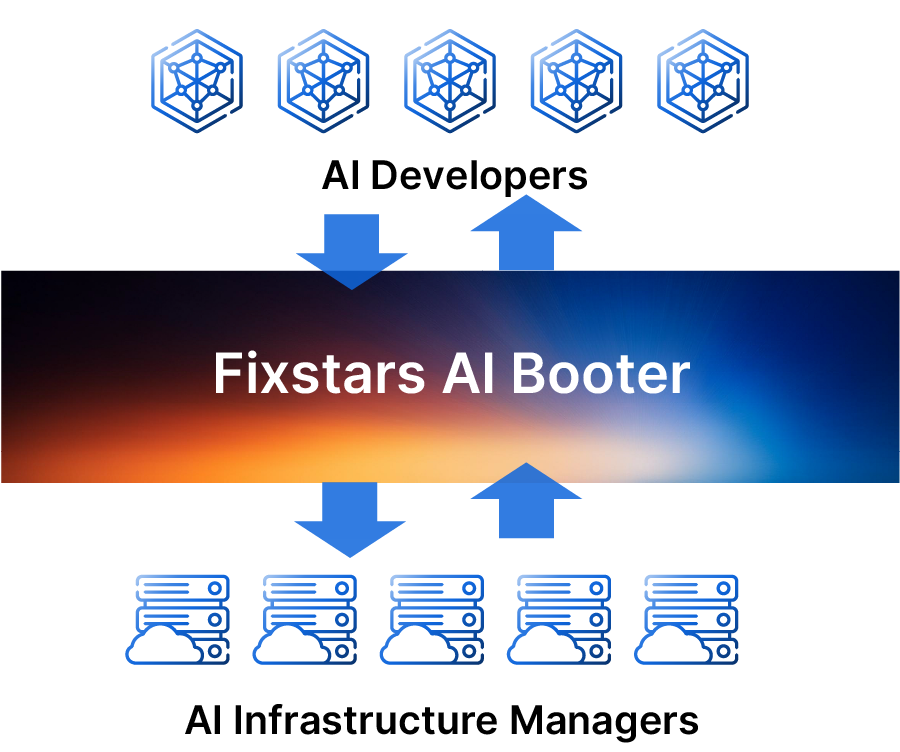
What is Fixstars AIBooster ?
Simply install Fixstars AIBooster on your GPU servers to gather detailed performance data from active AI workloads and clearly visualize bottlenecks.
- Monitors and visualizes performance of AI training and inference.
- Identifies bottlenecks and performance issues.
- Provides a suite of tools for automatic acceleration based on collected performance observation data.
- Based on data provided by Performance Observability, users can manually accelerate their AI workloads for further performance improvements.
(based on our actual project)
(based on our actual projects)
Performance Observability
- Efficiently collects hardware and AI workload data as time-series.
- Supports multiple platforms (AWS, Azure, GCP, and on-premises), seamlessly monitoring diverse system architectures in one place.
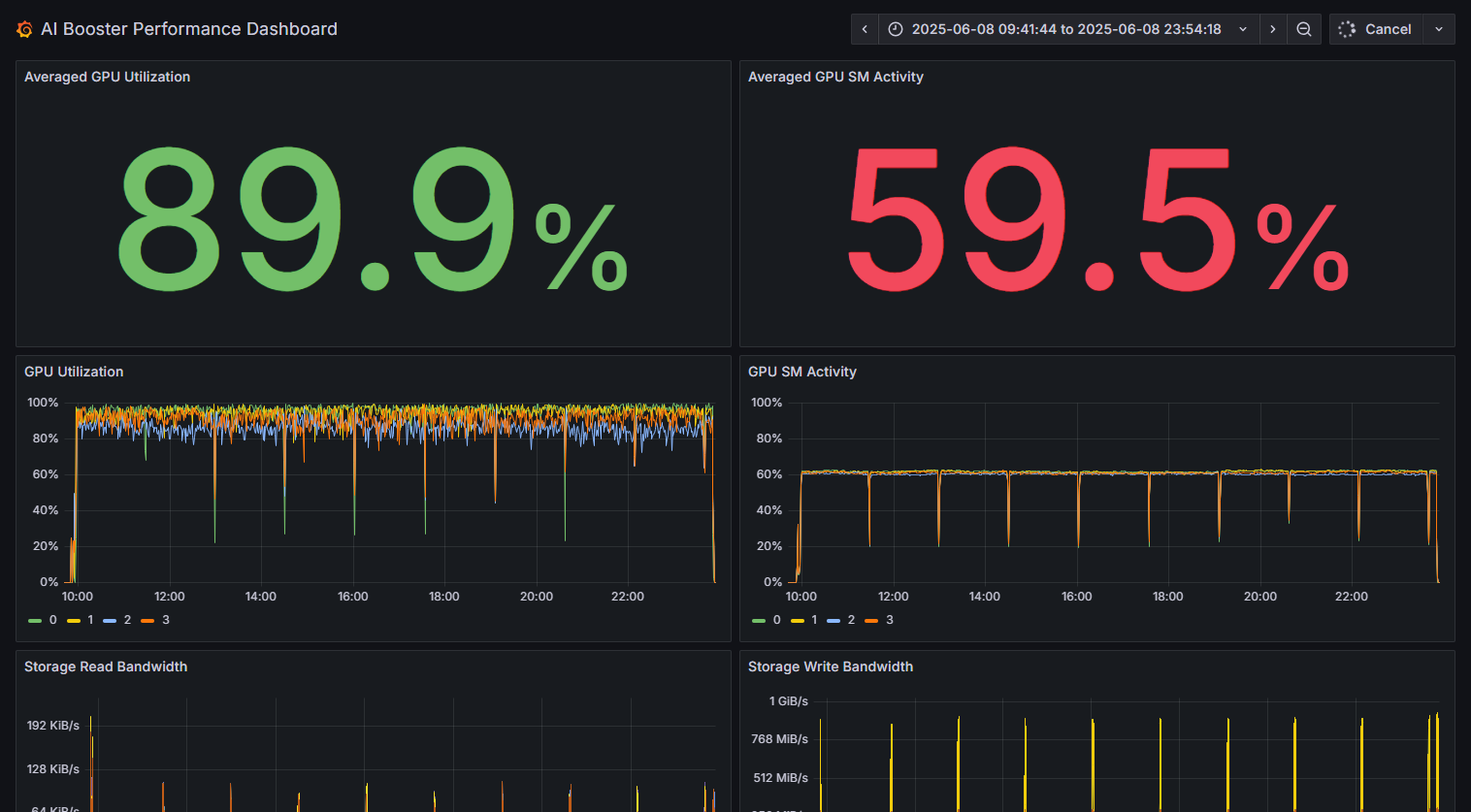
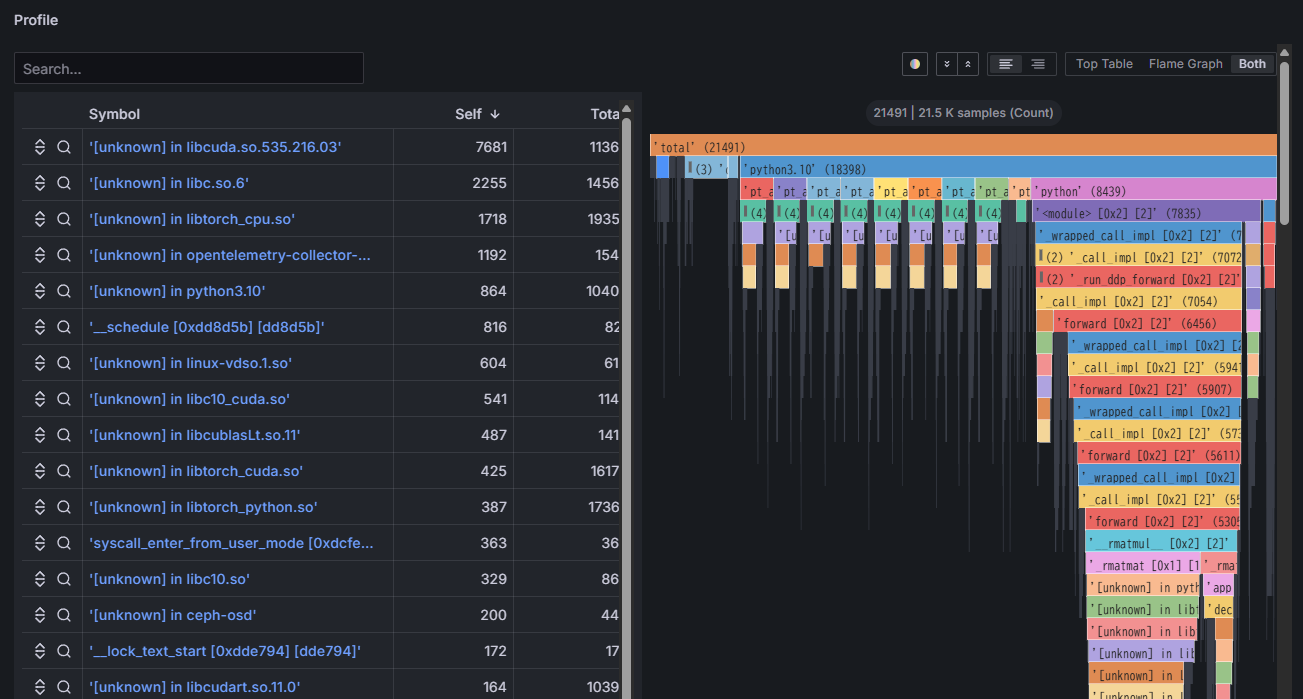
- Continuously saves flame graphs, breaking down application processing time to visualize internal processing details.
- Identifies which functions or libraries in the program are bottlenecks.
- Analyzes differences in application configurations under varying hardware utilization conditions.
Performance Intelligence
Data Analysis
- Calculates training efficiency (identifies potential for acceleration)
- Identifies areas needing acceleration from performance data
Acceleration
- Provides a suite of tools for automatic acceleration based on performance analysis.
- Offers necessary documentation to assist users in achieving manual acceleration.
Performance Engineering Services (Contact us for details)
Fixstars acceleration experts will improve your performance based on AIBooster analysis data, tailored to your environment and requirements.
Examples of Training Acceleration
- MHyperparameter Tuning (Learn more)
- Model Compression
- Applying appropriate parallelization methods for AI models
- Optimizing communication library parameters
- Improving memory bandwidth efficiency through re-computation
Examples of Inference Acceleration
- Fully Automated Inference Acceleration (Learn more)
- Automatic Mixed Precision Quantization
We provide the ZenithTune library, which helps you achieve peak performance with minimal coding, unlocking your application's full potential.
Learn more about ZenithTune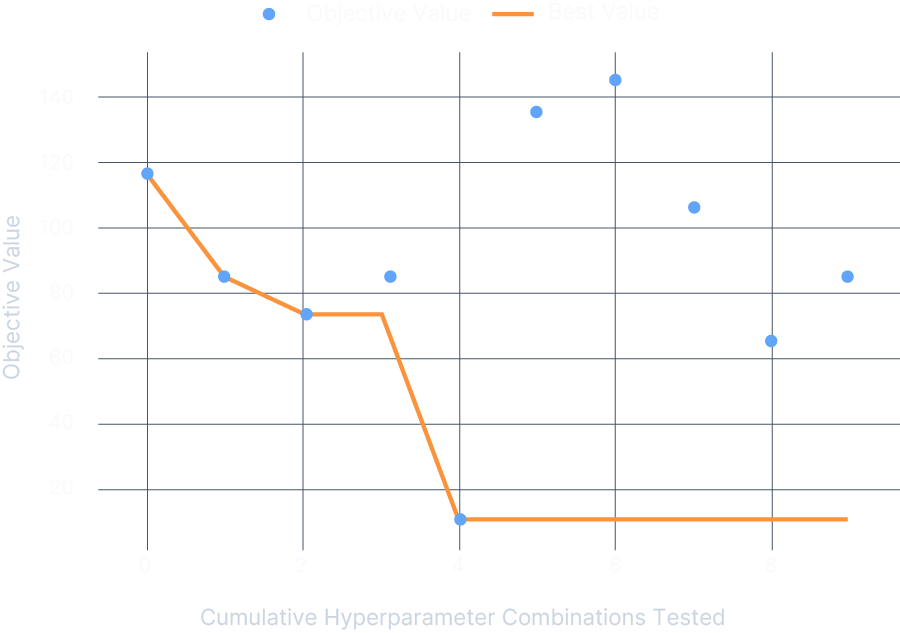
Challenges in Accelerating Deep Learning Model Inference on NVIDIA GPUs
- Complex Model Structures: The latest AI models have massive and intricate architectures.
- Limitations of Manual Optimization: Manually converting every pattern is too time-consuming and impractical.
- Need for Specialized Knowledge: Deep technical knowledge and experience with GPUs and TensorRT are required.
AcuiRT fully automates the conversion of AI models built with PyTorch into TensorRT. It dramatically reduces development time and boosts inference speed without requiring specialized expertise.
Learn more about AcuiRT
PyTorch Model
Complex multi-module structure
Automatic Structure Analysis
Automatically understands the module structure
Step-by-Step Optimization
Executes optimization completely automatically
Optimized Model
Immediately ready for useProven Performance Improvements
-
Broadcasting Company - LLM 70B Continued Pre-training

-
Telecom Company - LLM 70B Continued Pre-training

-
LLM7B Model Training

-
LLM Single-batch Inference

-
LLM Multi-batch Inference

Note: These results include both automatic accelerations by Fixstars AIBooster and additional manual accelerates based on collected performance data.
Whitepaper

Visualizing and Improving GPU Utilization in Autonomous Driving AI Development
A record of technical collaboration with Sony Honda Mobility, using AIBooster to visualize and improve GPU utilization in their autonomous driving AI development environment
Download Free
Revolutionizing AI Development Efficiency Through GPU Optimization with Fixstars AIBooster
A hands-on guide to overcoming the hidden GPU-utilization challenges most companies miss, with actionable strategies to boost AI efficiency.
Download Free
NVIDIA H200: AI Acceleration and Performance Engineering in Practice
This white paper explores proven methods to harness the full power of the latest GPUs and accelerate real-world AI workloads.
Download Free
Performance Engineering with
Fixstars AIBooster

Detect hidden bottlenecks and automatically accelerate your AI workloads.
Achieve further acceleration manually by utilizing acquired performance data.