

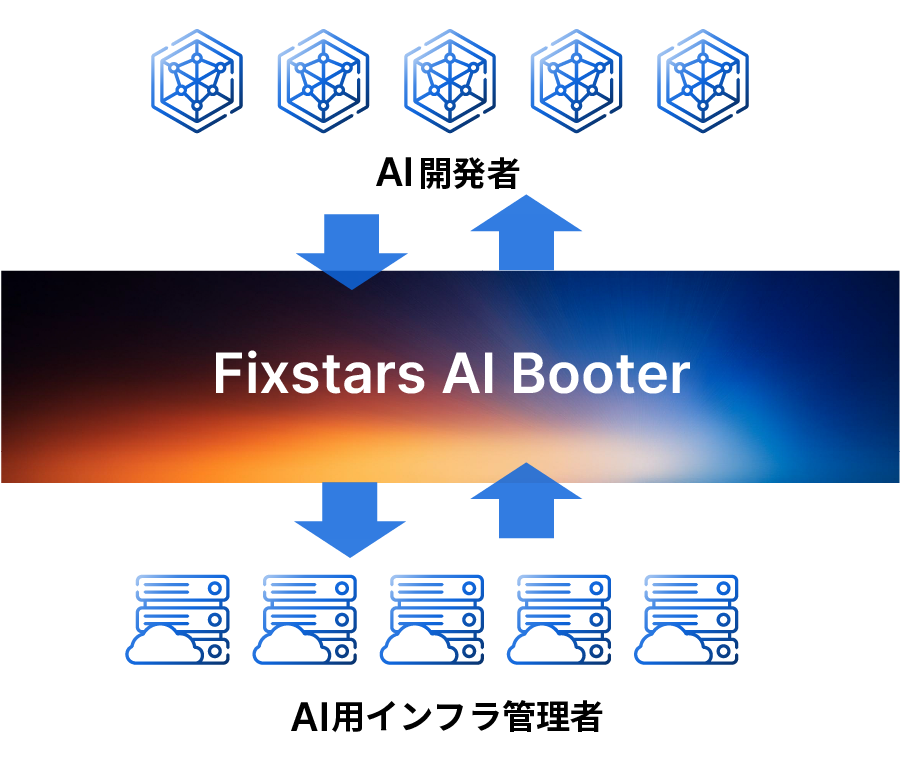
Fixstars AIBoosterとは
GPUサーバーに
-
AI学習や
推論などの パフォーマンス情報を 常に 監視・保存 -
性能の
劣化や 処理の ボトルネックなどを 可視化
-
パフォーマンス観測で
収集された データを もとに、 自動で 高速化する ための ツール群を 提供 -
Performance
Observabilityが
提供する データを もとに、 ユーザーが 手動で 高速化する ことで、 更なる パフォーマンス改善が 可能
パフォーマンス観測機能
-
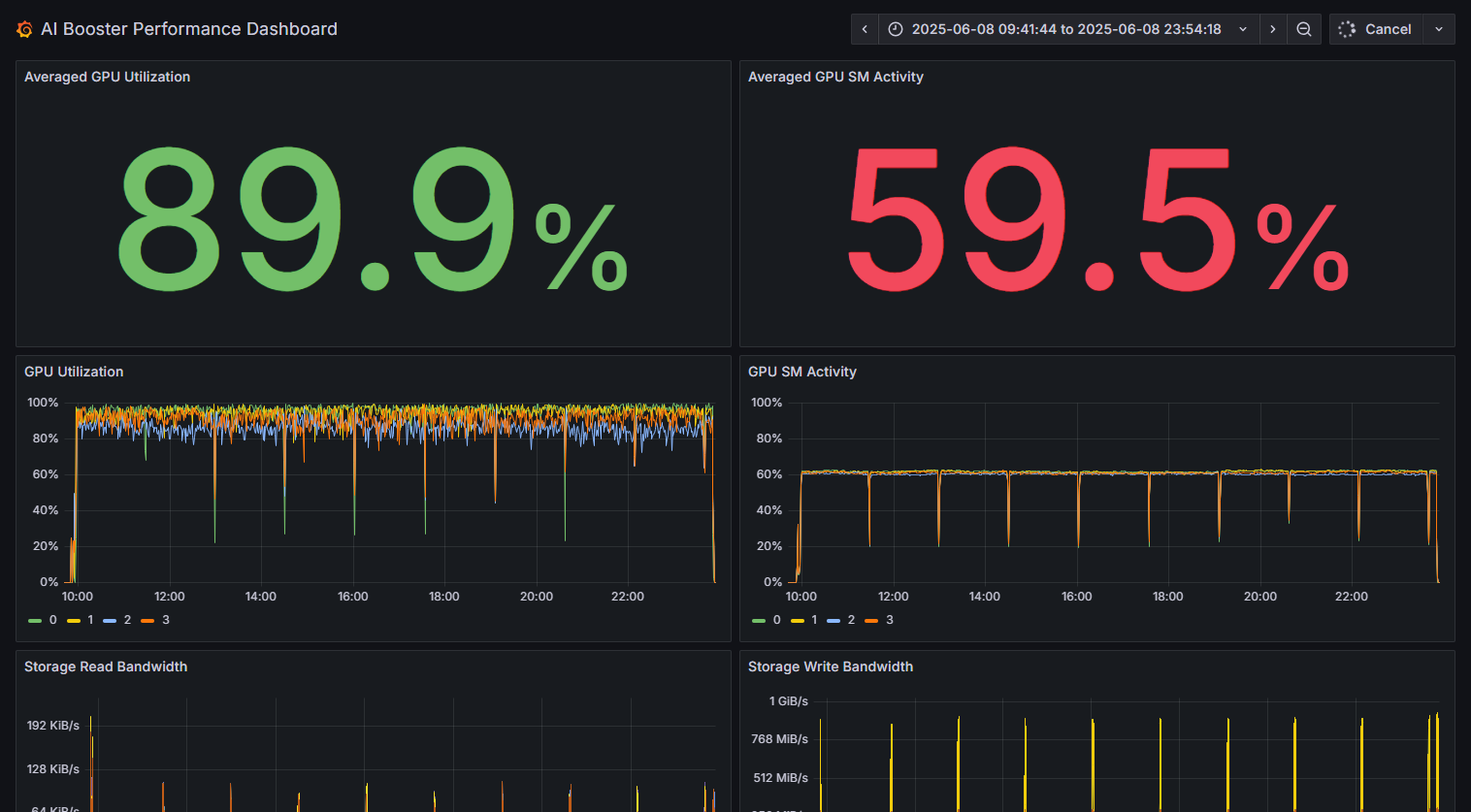
GPU、
CPU、 メモリ、 NIC、 PCIe、 ストレージなどの 情報を 集約して 時系列で 管理 -
オーバーヘッドを
極力抑え、 システムに 常駐して パフォーマンスデータを 継続して 取得
-
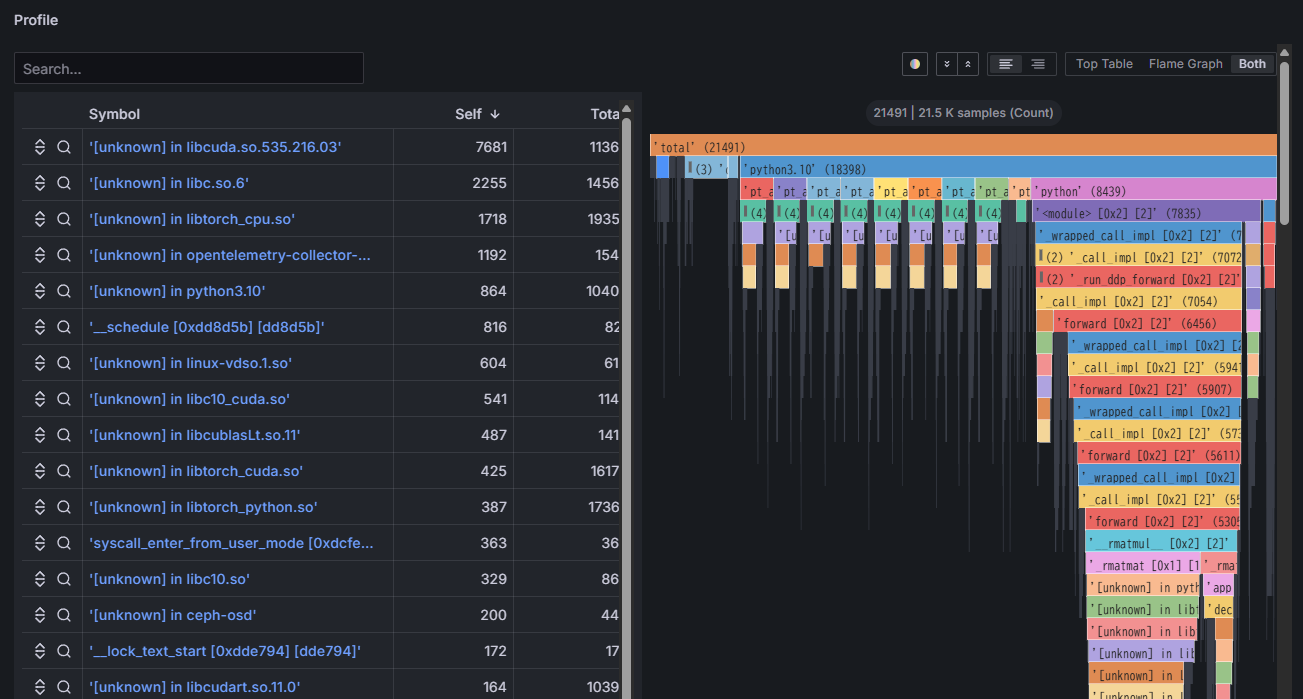
実行している
アプリケーションの 処理時間を 100と して、 アプリケーション内部の 処理の 内訳を ブレイクダウンして 可視化 -
プログラムの
うちの どの 関数、 どの ライブラリが ボトルネックに なっているか -
ハードウェアの
利用状況が 良い 場合・悪い 場合に、 アプリケーション構成の 違いは あるか
パフォーマンス改善機能
分析
POビューワーを
高速化
-
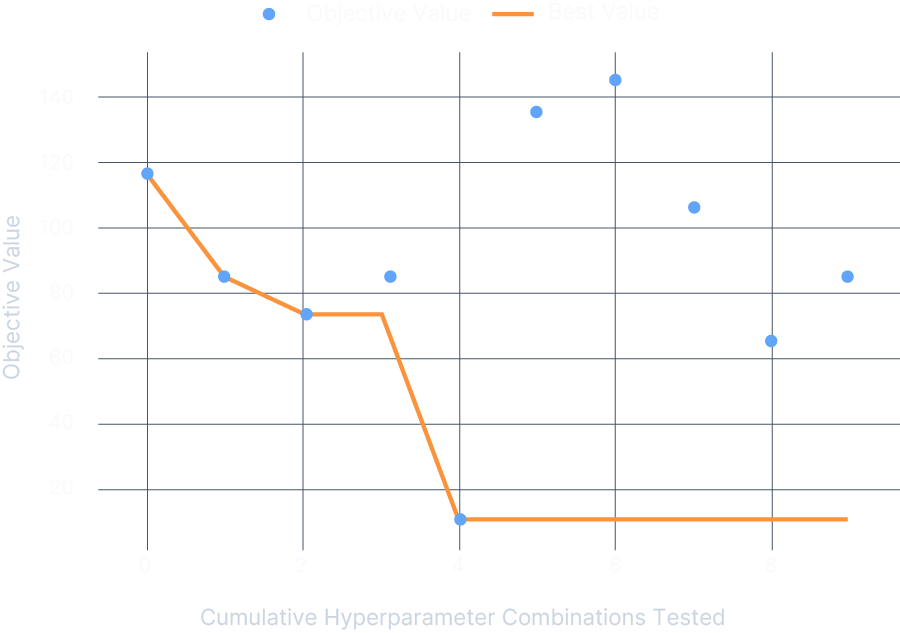
分析結果を
もとに、 自動で 高速化する ための ツール群を 提供 -
高速化に
必要な ドキュメントを 提供。 これを 利用して、 ユーザーが 手動で 高速化を 実現可能
パフォーマンスエンジニアリングサービス(要問い合わせ)
さらなる
アプリケーションの
深層学習モデルの
- 複雑なモデル構造:最新AIモデルは巨大で複雑な構造
- 手動最適化の限界:全パターンの手動変換は工数が膨大で現実的でない
- 専門知識の必要性:GPUやTensorRTの深い技術知識と経験が必要
PyTorchで

PyTorchモデル
複雑なマルチモジュール構造
自動構造解析
モジュール構造を自動把握
段階的最適化
完全自動で最適化を実行
最適化済みモデル
すぐに利用可能Fixstars AIBoosterによる高速化実績
-
放送会社様・LLM70Bモデル継続事前学習

-
通信会社様・LLM70Bモデル継続事前学習
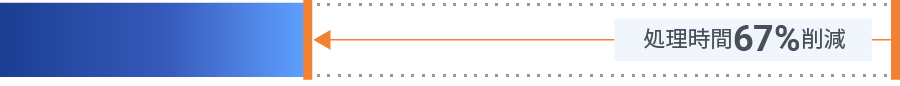
-
LLM7Bモデル学習

-
LLMシングルバッチ推論

-
LLMマルチバッチ推論

※Fixstars AIBoosterの自動高速化と、取得したパフォーマンスデータを元にした手動高速化の両方の結果を含む
ホワイトペーパー

自動運転AI開発環境におけるGPU利用効率の可視化と改善
ソニー・ホンダモビリティの

Fixstars AIBoosterを用いたGPU最適化によるAI開発効率の革新的向上
多くの

NVIDIA H200によるAI高速化とパフォーマンスエンジニアリングの実践
最新GPUの
