コスト分析ビューは、AIBoosterが収集した各種パフォーマンス情報を、オペレーションコストに責任を持つ事業リーダー向けに可視化したダッシュボードです。
このデモではFixstars社内のGPUサーバー(NVIDIA H100 x 4)にインストールされたAIBoosterのコスト分析ビューを、お使いのブラウザで実際に閲覧いただけます。
このデモで体験できること:
- Llama3 8Bの教師ありファインチューニングを実行した際の、コスト分析ビューを閲覧
- 観測期間中のシステム全体のコスト(トータルコスト)、GPU未使用にもかかわらず発生してしまっているコスト(アイドリング時コスト)、最適化等によりGPUを効率よく使えている時間を金額に換算したもの(Boost Bonus)、などの指標を確認
- 時間範囲を指定することで、特定時間の上記指標の変化を分析
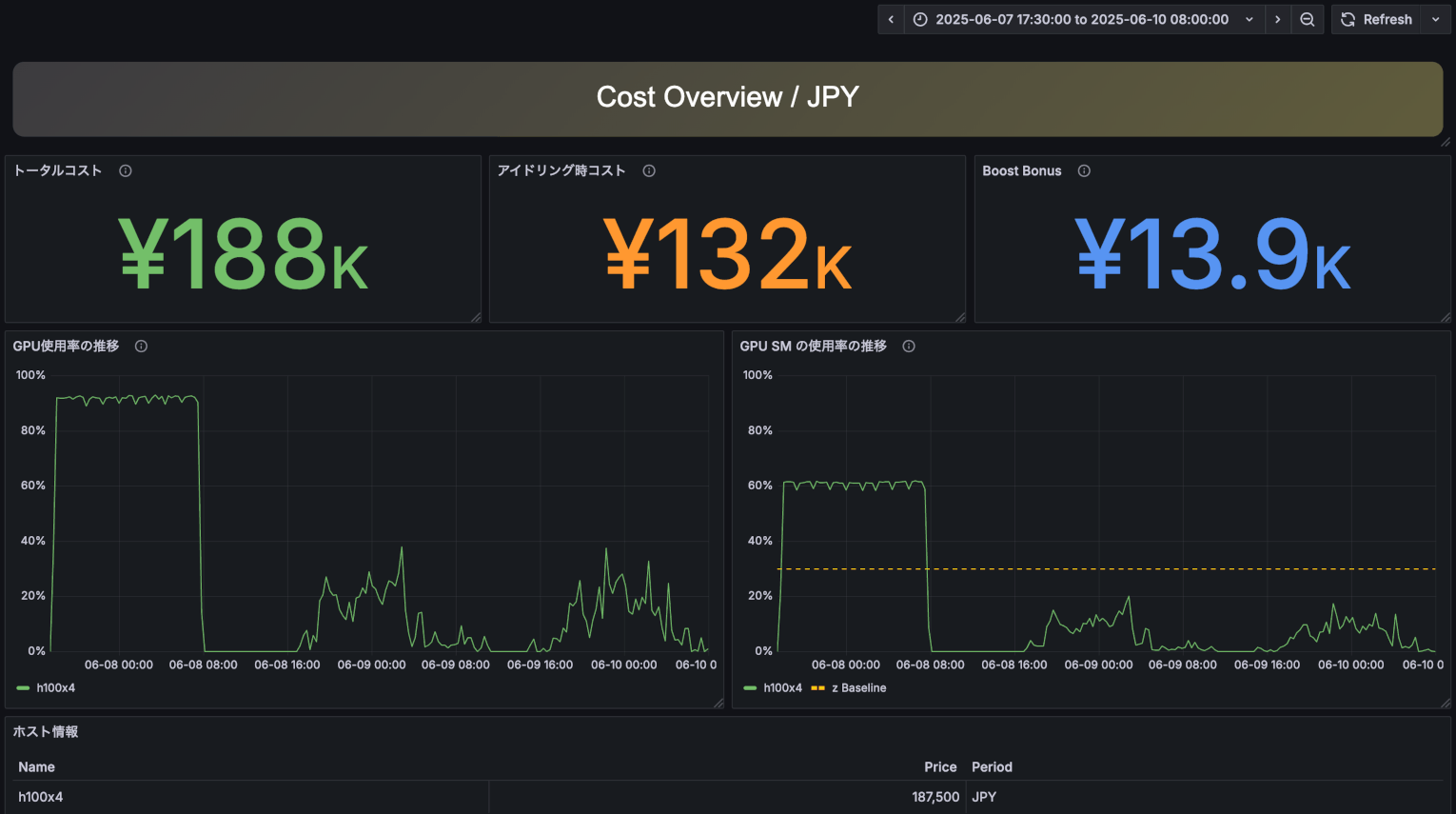
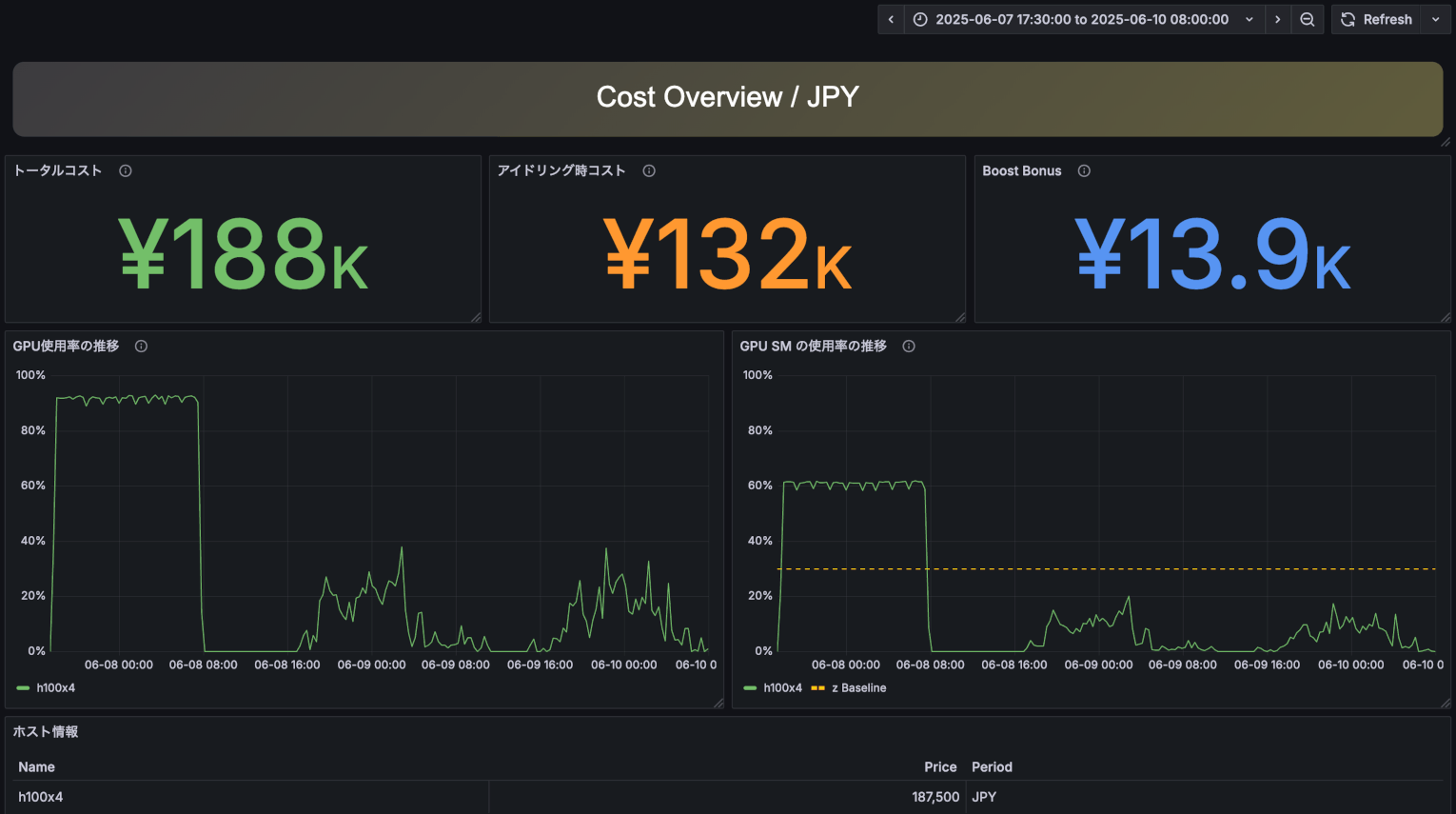
コスト分析ビューの上段左のパネルでは、観測期間中にシステムを稼働させた際に発生したコストの総額を表示しています。表示されているコストは、一般的なクラウドサービスのレートを元に算出されています。製品版では、ユーザー自身が実環境に合わせたコスト計算式を設定可能です。
上段中央のパネルは、GPUが全く使用されていない時間に発生してしまっているコストを示したものです。GPUを常に100%使うのは難しいですが、GPUを有効活用するために、この「アイドリング時コスト」の削減を一つの指標にしてください。
上段右のパネルは、GPUを一般的な基準よりも高効率に活用した際にその価値を金額換算したものです。簡単にいえば、この「Boost Bonus」分だけ、「お得」にGPUを活用できていることになります。Boost Bonusは、GPU内部の計算コアが30%活用されている状態を基準値として、そこからの増分に対して時間単価を掛けて算出しています。この指標はAIBooster のPI(Performance Intelligence)の機能で改善可能です。

コスト分析ビューの上段左のパネルでは、観測期間中にシステムを稼働させた際に発生したコストの総額を表示しています。表示されているコストは、一般的なクラウドサービスのレートを元に算出されています。製品版では、ユーザー自身が実環境に合わせたコスト計算式を設定可能です。
上段中央のパネルは、GPUが全く使用されていない時間に発生してしまっているコストを示したものです。GPUを常に100%使うのは難しいですが、GPUを有効活用するために、この「アイドリング時コスト」の削減を一つの指標にしてください。
上段右のパネルは、GPUを一般的な基準よりも高効率に活用した際にその価値を金額換算したものです。簡単にいえば、この「Boost Bonus」分だけ、「お得」にGPUを活用できていることになります。Boost Bonusは、GPU内部の計算コアが30%活用されている状態を基準値として、そこからの増分に対して時間単価を掛けて算出しています。この指標はAIBooster のPI(Performance Intelligence)の機能で改善可能です。
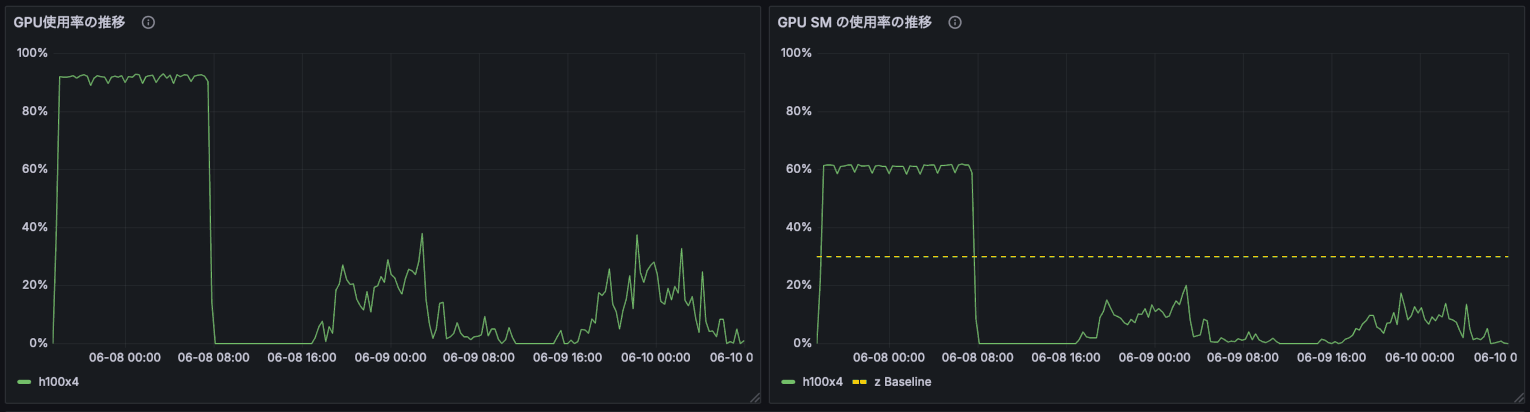
GPU稼働率が90%であっても、内部のSMは60%しか使用されていないことがあります。
この場合、このシステムに高速化の余地があることを意味します。
ダッシュボード右上部のドロップダウンリストから、観測対象期間を変更できます
時系列グラフ上で確認したい範囲をクリックしてドラッグすることで、詳細な時間範囲を指定できます。指定した範囲で再描画され、より細かな分析が可能になります。
- 「デモを開始」ボタンをクリックします
- ブラウザでPerformance Observability(PO)のコスト分析ビューが表示されます
- 各パネルを自由に閲覧してください
※製品版では各パネルの大きさ、グラフの種類、表示するデータ、などを自由にカスタマイズできます。
パフォーマンス分析ビューは、AIBoosterが収集した各種パフォーマンス情報を、AI開発者向けに可視化したダッシュボードです。
このデモではFixstars社内のGPUサーバー(NVIDIA H100 x 4)にインストールされたAIBoosterのパフォーマンス分析ビューを、お使いのブラウザで実際に閲覧いただけます。
このデモで体験できること:
- パフォーマンス分析ビューを閲覧
- GPU利用状況、CPU利用状況など、様々なパフォーマンス指標を時系列グラフで確認
- ソフトウェア内部のどの関数やライブラリがどのぐらい時間がかかっているのか判別
- 時間範囲を指定することで、特定時間の上記指標の変化を分析
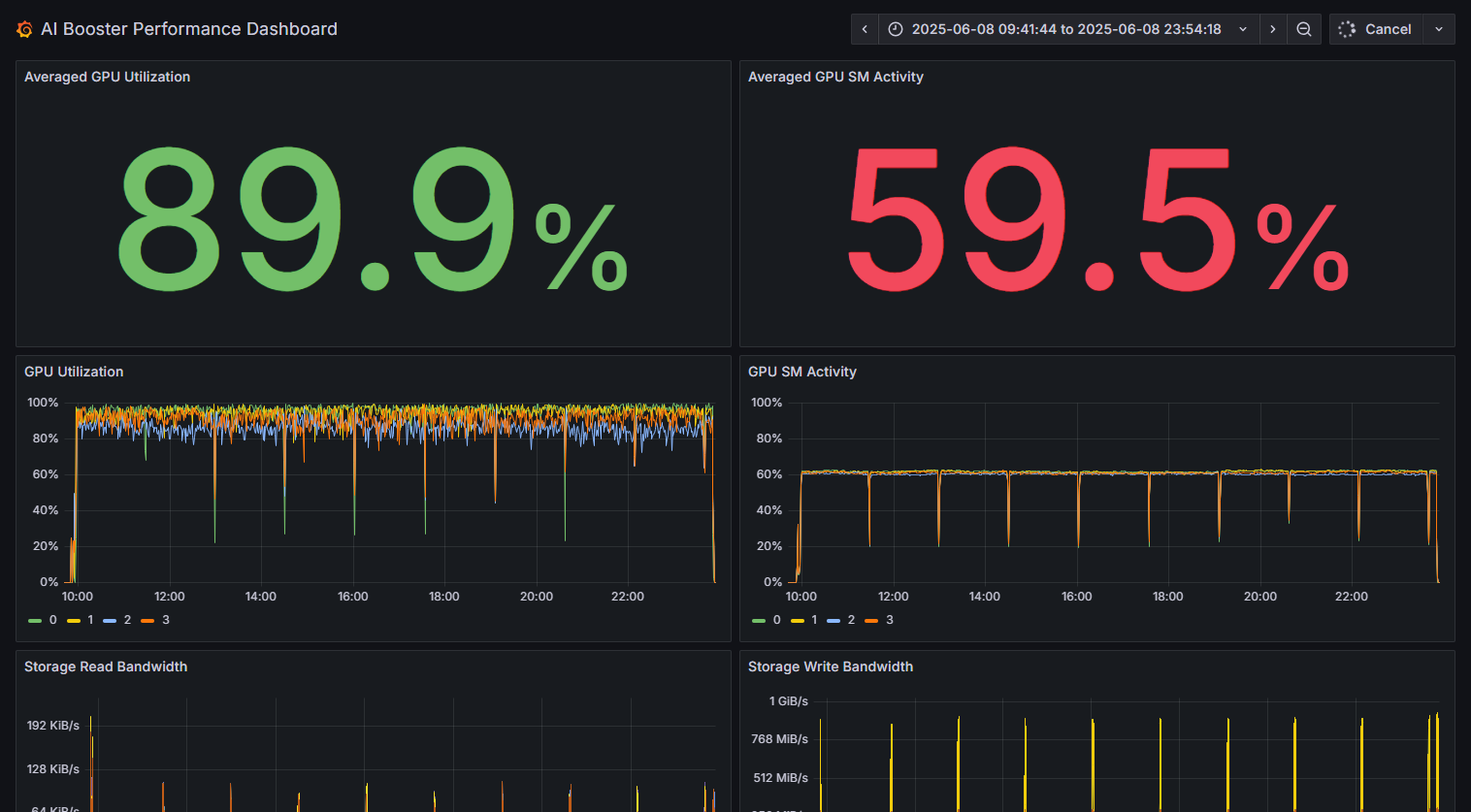
パフォーマンス分析ビューの一番上では、観測期間中にシステム上で動作したワークロード全体の”GPU Utilization”(左パネル:GPUの稼働率)が表示されます。また、右のパネルにおいて、SMはStreaming Multiprocessorの略です。1つのGPUは多数のSMで構成されており、このパネルではSMレベルでの稼働率を表示します。どちらも100%に近い値であれば、GPUが効率的に使用されていることになります。
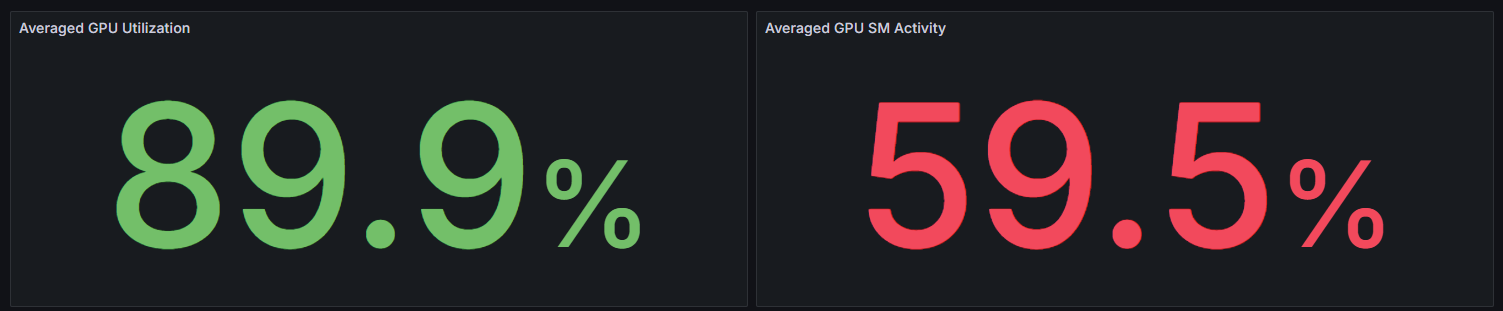
GPU稼働率が89.9%であっても、内部のSMは59.5%しか使用されていないことがあります。
この場合、このシステムに高速化の余地があることを意味します。
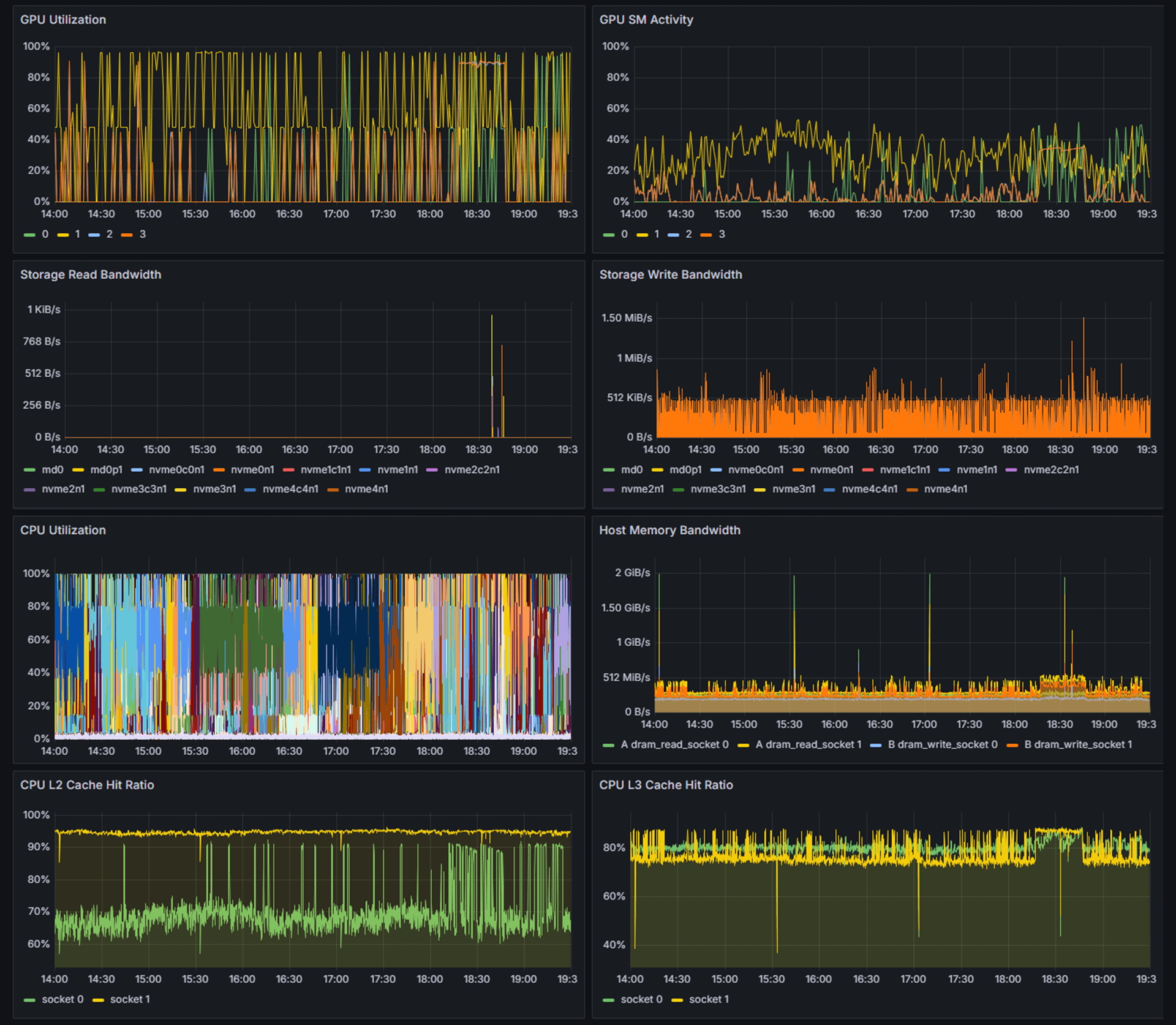
続くパネルでは、以下の8種のパフォーマンス指標を時系列グラフとして表示しています。
- GPU Utilization
- CPU Utilization
- CPU L2 Cache Hit Ratio
- Interconnect Send Bandwidth
- Storage Read Bandwidth
- GPU SM Activity
- Memory Bandwidth
- CPU L3 Cache Hit Ratio
- Interconnect Recv Bandwidth
- Storage Write Bandwidth
フレームグラフとは、ソフトウェアの処理にかかった時間を視覚化したもので、どの関数やライブラリがどれだけの時間を消費しているかを直感的に表します。縦軸は処理の階層、横軸は実行時間の割合を示し、長いバーほど時間を多く使っていることを意味します。性能改善やボトルネックの特定に役立ちます。
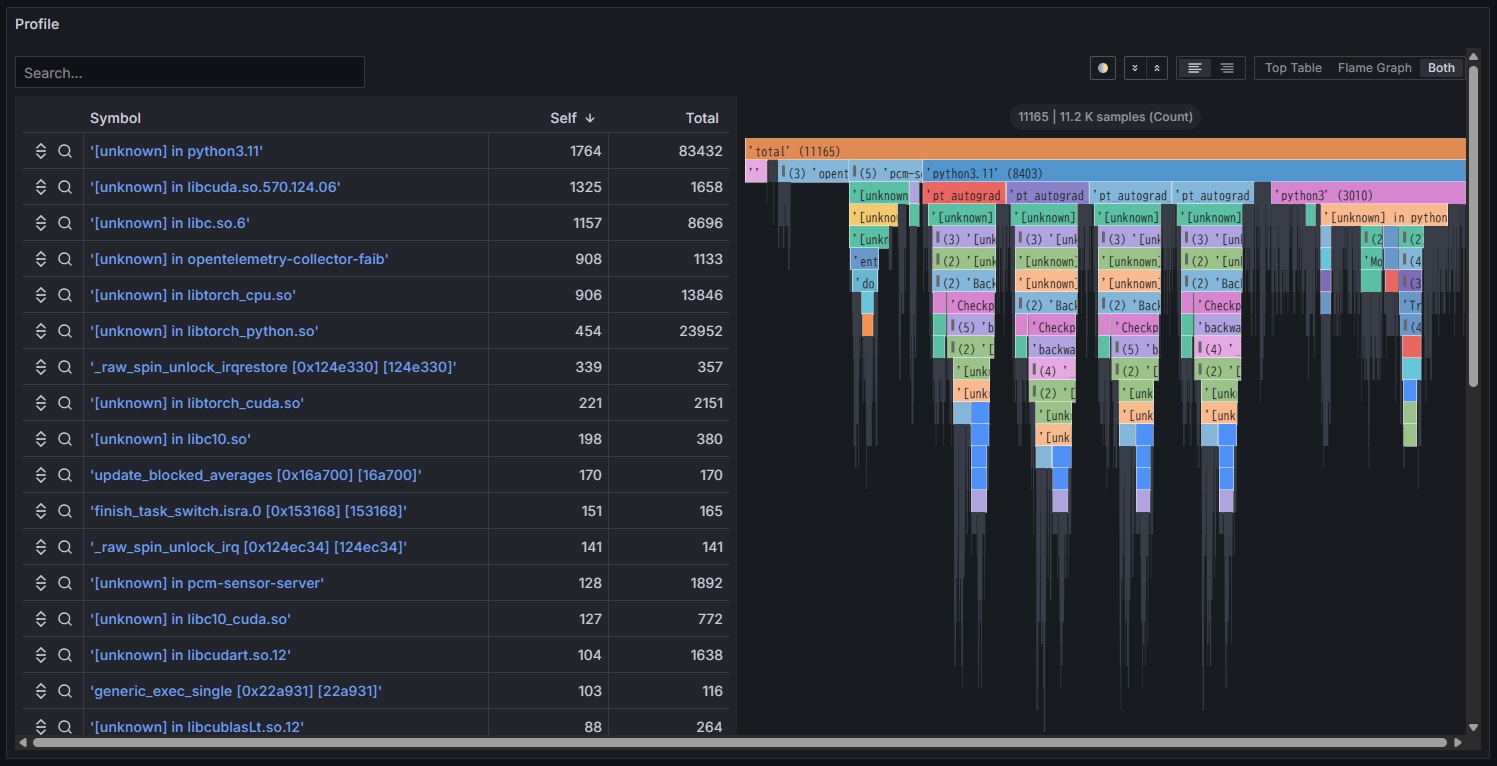
ライブラリや関数名の表とフレームグラフの両方が横並びで表示されます。それぞれを単独で表示することも可能です
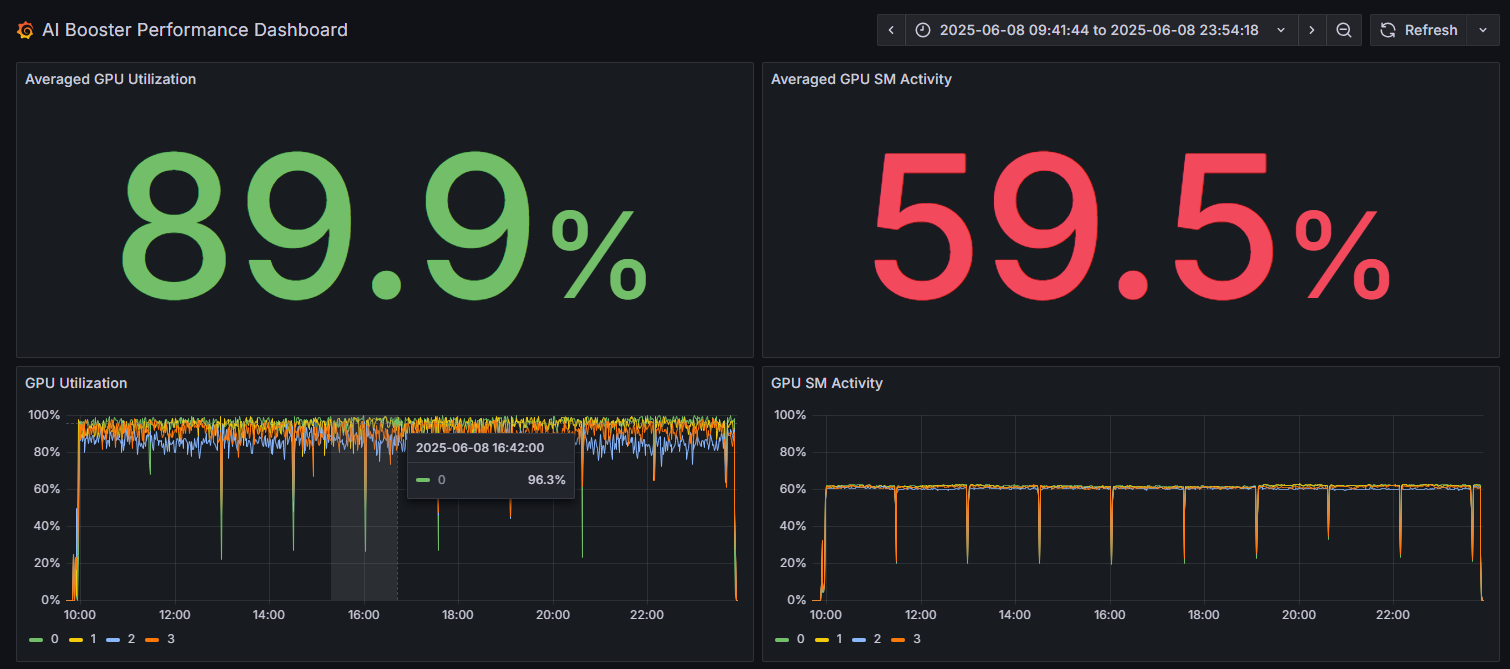
ダッシュボード右上部のドロップダウンリストから、観測対象期間を変更できます
時系列グラフ上で確認したい範囲をクリックしてドラッグすることで、詳細な時間範囲を指定できます。指定した範囲で再描画され、より細かな分析が可能になります。
- 「デモを開始」ボタンをクリックします
- ブラウザでPerformance Observability(PO)のパフォーマンス分析ビューが表示されます
- 各パネルを自由に閲覧してください
※製品版では各パネルの大きさ、グラフの種類、表示するデータ、などを自由にカスタマイズできます。