
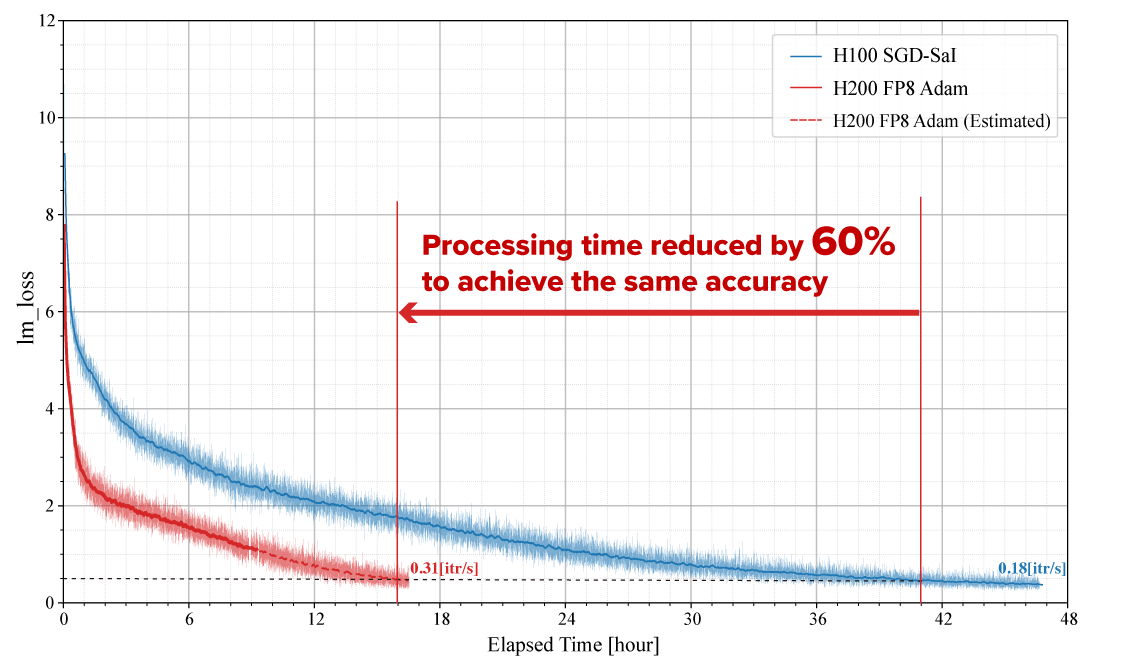
IRVINE, California – June 12, 2025 – Fixstars Corporation (TSE Prime: 3687, US Headquarters: Irvine, CA), a leading company in performance engineering technology, is pleased to announce successful verification of its "Fixstars AIBooster" (hereinafter, AIBooster) on Sakura Internet Inc.’s newest GPU-equipped servers, "Koukaryoku PHY," featuring NVIDIA's latest H200 GPUs.

IRVINE, California – June 17, 2025 – Fixstars Corporation (TSE Prime: 3687, US Headquarters: Irvine, CA), a leading company in performance engineering technology, has commenced rental services for "Fixstars AIStation" (hereinafter, AIStation), a private AI utilization workstation that allows secure use of the latest AI in a local environment.

IRVINE, California – Jun 10, 2025 – Fixstars Corporation (TSE Prime: 3687, US Headquarters: Irvine, CA),a leading company in performance engineering technology, today announced that a joint research group including Fixstars Corporation, along with RIKEN, Tokyo Tech, Nippon Telegraph and Telephone Corporation, and Fujitsu Limited, has achieved the world's No. 1 ranking in the BFS (Breadth-First Search) division of Graph500, an international supercomputer performance ranking for large-scale graph analysis, using the supercomputer "Fugaku".
IRVINE, California – May 15, 2025 – Fixstars Corporation (TSE Prime: 3687, US Headquarters: Irvine, CA), a leading company in performance engineering technology, is pleased to announce the launch of a free downloadable version of "Fixstars AI Booster (FAIB)" from its official website.
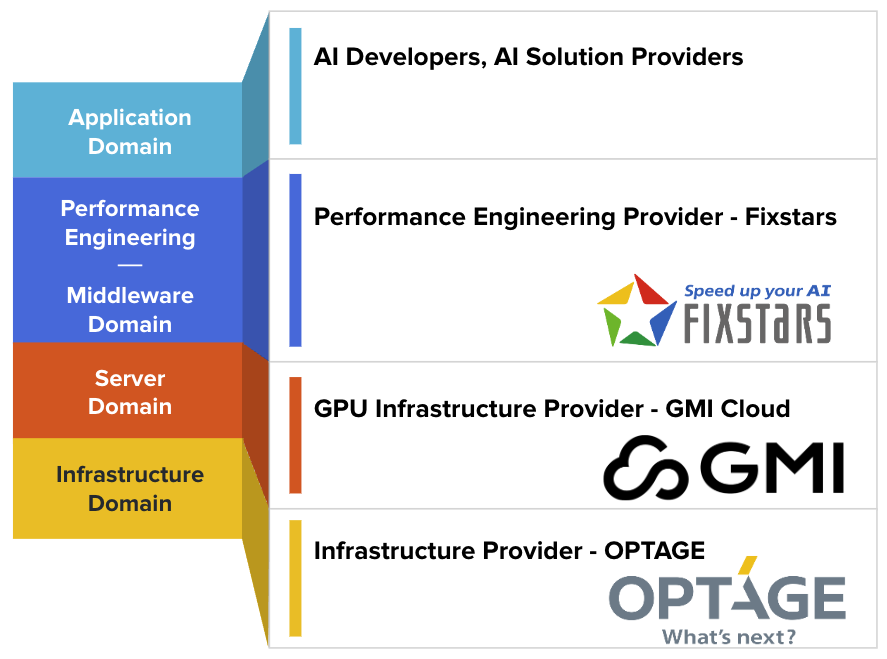
IRVINE, California. – April 15, 2025 – Fixstars Corporation (TSE Prime: 3687, US Headquarters: Irvine, USA), a company dedicated to advancing AI technologies through world-class performance engineering, today announced its participation as an AI software technical advisor in the strategic partnership between Optage Inc. (Headquarters: Osaka, Japan) and GMI Cloud, Inc. (Headquarters: San Jose, USA).

TOKYO, JAPAN – March 3, 2025—Fixstars Corporation (TSE Prime: 3687), a global leader in software acceleration technologies, today announced that its corporate tagline has been changed from “Speed up your Business” to “Speed up your AI.”

TOKYO, JAPAN – February 27, 2025 – Fixstars Corporation (TSE Prime: 3687), a global leader in AI-powered software development and acceleration, today announced the open-source release of its Multi-View Stereo (MVS) software, "CUMVS (cuda-multi-view-stereo)," under the Apache License 2.0. CUMVS is designed to accelerate the realization of digital twins of the physical world.

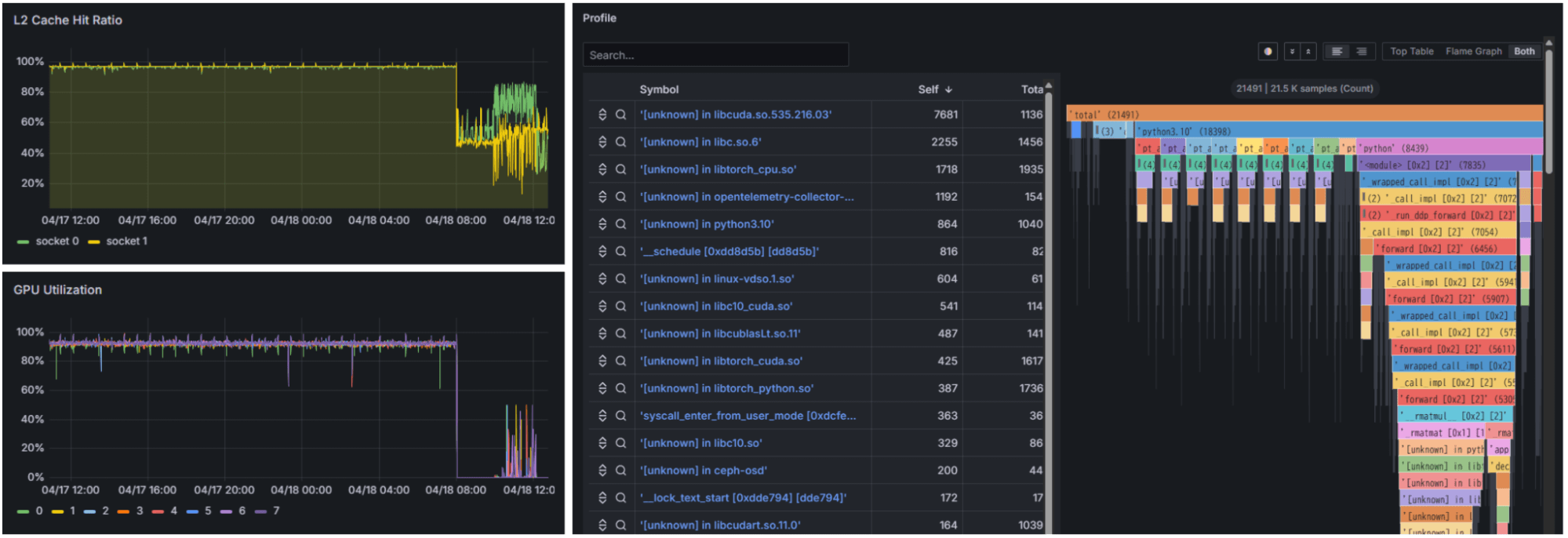
TOKYO, JAPAN – February 12, 2025 – Fixstars Corporation (TSE Prime: 3687), a global leader in AI-powered software development and acceleration, today announced its partnership with OPTAGE Inc. on their new AI Data Center (AI DC) project.
A subsidiary of Fixstars Corporation, Smart Opinion, Inc. (Headquarters: Minato-ku, Tokyo; President and CEO: Kenji Yamanami), a company dedicated to developing "Smaopi," an AI-powered breast cancer screening tool that uses AI technology to analyze ultrasound image of the breast to detect suspected breast cancer through image diagnosis, is pleased to announce that it has been selected as one of five startups to participate in Phase 2 of the "HealthTech Gateway 'AI Medical in the US'" program.
TOKYO, JAPAN – January 23, 2025 – Fixstars Corporation, a global leader in AI-driven software development and acceleration, today announced its participation in the "AWS Japan Generative AI Practical Application Promotion Program," provided by Amazon Web Services (AWS) Japan G.K.
TOKYO, JAPAN, Jan. 8, 2025 — Fixstars Corporation, a global leader in AI-driven software development and acceleration, today announced the launch of “AI Booster”. “AI Booster” is an AI acceleration platform designed to instantly and continuously extract maximum performance from AI applications running on a wide range of GPU environments.
Irvine, CA – July 8th, 2024 – Fixstars Solutions Inc., a global leader in acceleration technologies, is excited to announce its participation in the upcoming SEMICON West 2024, from July 9th to 11th in San Francisco.
Irvine – November 14th, 2023 - Fixstars Solutions Inc., a global leader in acceleration technologies, has announced Fixstars Corporation's tremendous achievement: supercomputer Fugaku has been ranked number one in the world for eight consecutive terms in the BFS (Breadth-First Search) category of Graph500. A joint research group consisting of RIKEN, Kyushu University, Fixstars Corporation, Nippon Telegraph and Telephone Corporation (hereinafter referred to as "NTT"), and Fujitsu Limited further improved measurement results of Graph500.
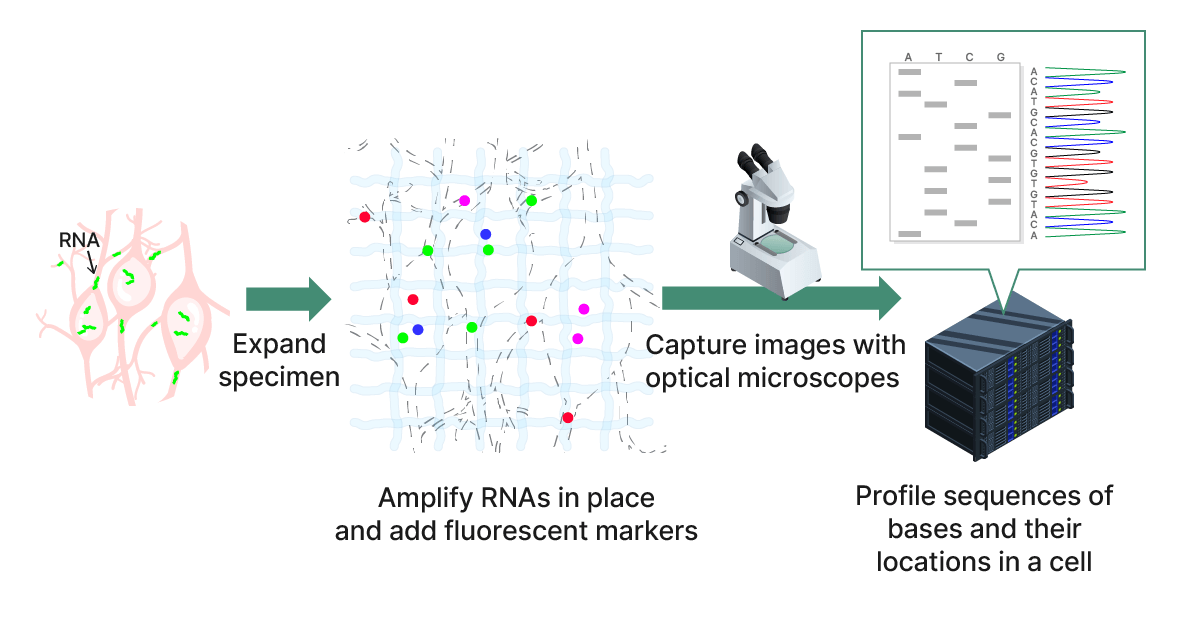
Irvine, CA- June 27th, 2023. The Weissman Lab, led by Dr. Irving Weissman, a professor at Stanford University in Pathology and Developmental Biology, will be working directly with Fixstars Solutions starting in July, 2023. Fixstars and Dr. Weissman will collaborate on in-situ sequencing research.
Irvine – January 29th, 2021 - Fixstars Solutions Inc., a global leader in acceleration technologies, announced that a research paper on expansion sequencing -- which is one of the in situ sequencing (ISS) methods -- was published online in the journal of science today.

The high-end GPU cluster server system used by Cold Spring Harbor Laboratory (CSHL) was delivered by Fixstars; Fixstars also provided software consultation to utilize the GPUs.
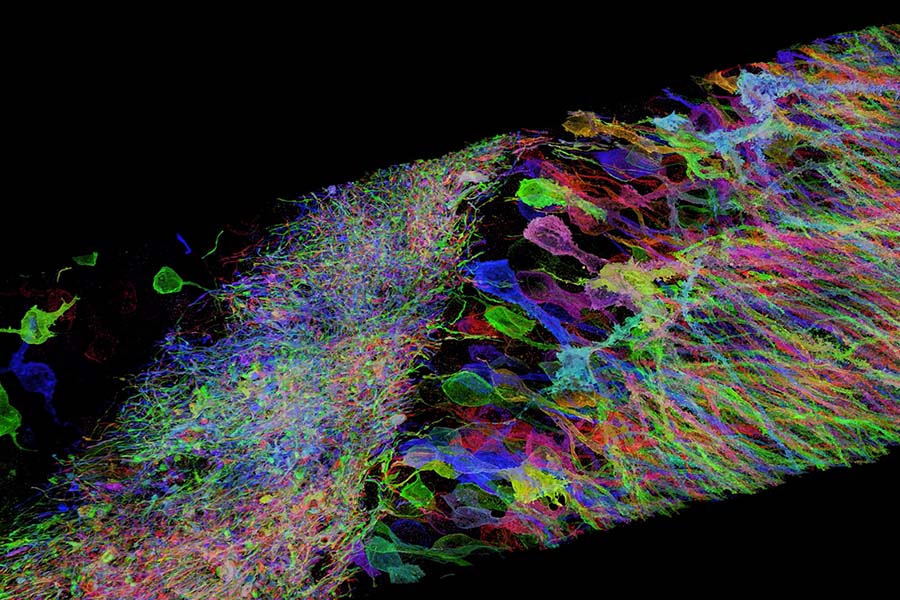
November 13th, 2018 — Cambridge, MA, USA — Fixstars Solutions Inc., a global leader in providing multi-core CPU/GPU/FPGA acceleration technology, announced today that it has released a software package for the Expansion Microscopy project which will be called “Expansion Microscopy Studio (ExM Studio)”. The software is free to use and is now available on their website: www.exm.studio . Fixstars will be accepting orders for “ExM ready” workstations/servers which will come preconfigured with ExM Studio — also available on their website.

June 26, 2017 — Tokyo, Japan — D-Wave Systems Inc. , the leader in quantum computing systems and software, and Fixstars Corporation of Japan today announced a collaboration to advance the growth of quantum computing. Fixstars is a leader in providing CPU/GPU/FPGA acceleration technologies, using its software parallelization and optimization expertise. Fixstars is now launching a professional service to help organizations realize the benefits and advantages of D-Wave quantum computers.